Transformacoes Groovy Prontas para Producao -- 3 Scripts Gerados em Uma Sessao
Groovy no SAP CPI: A Espinha Dorsal das Transformacoes
Scripts Groovy sao o mecanismo principal de transformacao de dados dentro do SAP Cloud Platform Integration. Toda vez que dados fluem entre dois sistemas com schemas diferentes, nomes de campos distintos, formatos de data, codigos de moeda ou valores de enumeracao diferentes, um script Groovy fica no meio e traduz. Nao e middleware opcional -- e o nucleo de toda integracao nao trivial.
Escrever esses scripts corretamente e mais dificil do que parece. Um script de transformacao para uso em producao precisa tratar campos nulos sem lancar NullPointerException, registrar informacoes suficientes para debug sem inundar o sistema de monitoramento, converter entre tipos de dados com seguranca, mapear valores de enumeracao de acordo com um dicionario de negocios definido e produzir uma saida que corresponda exatamente ao schema esperado pelo sistema downstream. Falhe em qualquer um desses requisitos e a integracao quebra em runtime, frequentemente com mensagens de erro cripticas que levam horas para diagnosticar.
O consultor SAP CPI tipico gasta entre 3 e 8 horas escrevendo uma unica transformacao Groovy de qualidade para producao, dependendo da complexidade dos schemas de origem e destino. Testes adicionam mais 2 a 4 horas. Multiplique isso pelas dezenas de transformacoes que um projeto tipico de integracao enterprise requer, e o desenvolvimento Groovy se torna um dos maiores itens de custo no plano do projeto.
O R2-CX muda essa equacao fundamentalmente. Em uma unica sessao, ele gerou tres scripts Groovy completos de transformacao -- cada um pronto para producao, cada um com tratamento completo de erros, cada um com logging estruturado -- em questao de segundos.
Script 1: Account Data Transformer (C4C para Canonico)
| Parametro | Valor |
|---|---|
| Sistema de Origem | SAP Cloud for Customer |
| Formato de Destino | JSON Canonico |
| Desafio Principal | Estruturas de endereco aninhadas, normalizacao de telefone |
| Tempo de Geracao | < 3 segundos |
O Problema
O SAP C4C armazena dados de conta em uma estrutura profundamente aninhada. O AccountID, nome e classificacao ficam no nivel raiz, mas enderecos estao enterrados dentro de uma colecao BusinessPartnerAddress, numeros de telefone vivem dentro de BusinessPartnerPhoneNumber com codigos de tipo, e o status do ciclo de vida da conta usa valores de enumeracao internos do SAP que nenhum sistema externo entende.
O formato canonico de destino esperado pelo data warehouse downstream requer uma estrutura plana com nomes de campo normalizados, codigos de pais ISO em vez de codigos de territorio SAP, numeros de telefone formatados em E.164 e labels de status legiveis em vez de inteiros de enumeracao.
O Que o R2-CX Gerou
O script gerado comeca com um bloco robusto de parsing que le o corpo da mensagem de entrada e desserializa usando o JsonSlurper do Groovy. Imediatamente apos o parsing, verifica a presenca de campos obrigatorios -- AccountID, AccountName e LifeCycleStatusCode -- e registra um warning com os nomes especificos dos campos ausentes se algum estiver faltando, em vez de produzir silenciosamente uma saida incompleta.
A secao de transformacao de endereco itera sobre a colecao BusinessPartnerAddress, identifica o endereco principal usando o flag DefaultIndicator e mapeia codigos de territorio SAP para codigos de pais ISO 3166-1 alpha-2 usando um mapa de lookup estatico. O script trata o caso comum onde nenhum endereco esta marcado como padrao fazendo fallback para o primeiro endereco da colecao, registrando essa decisao de fallback para fins de auditoria.
A normalizacao de telefone remove parenteses, hifens e espacos, depois adiciona o codigo de discagem do pais baseado no pais do endereco. O script trata ambos os casos onde o numero de telefone ja inclui um codigo de pais (comecando com "+") e onde nao inclui.
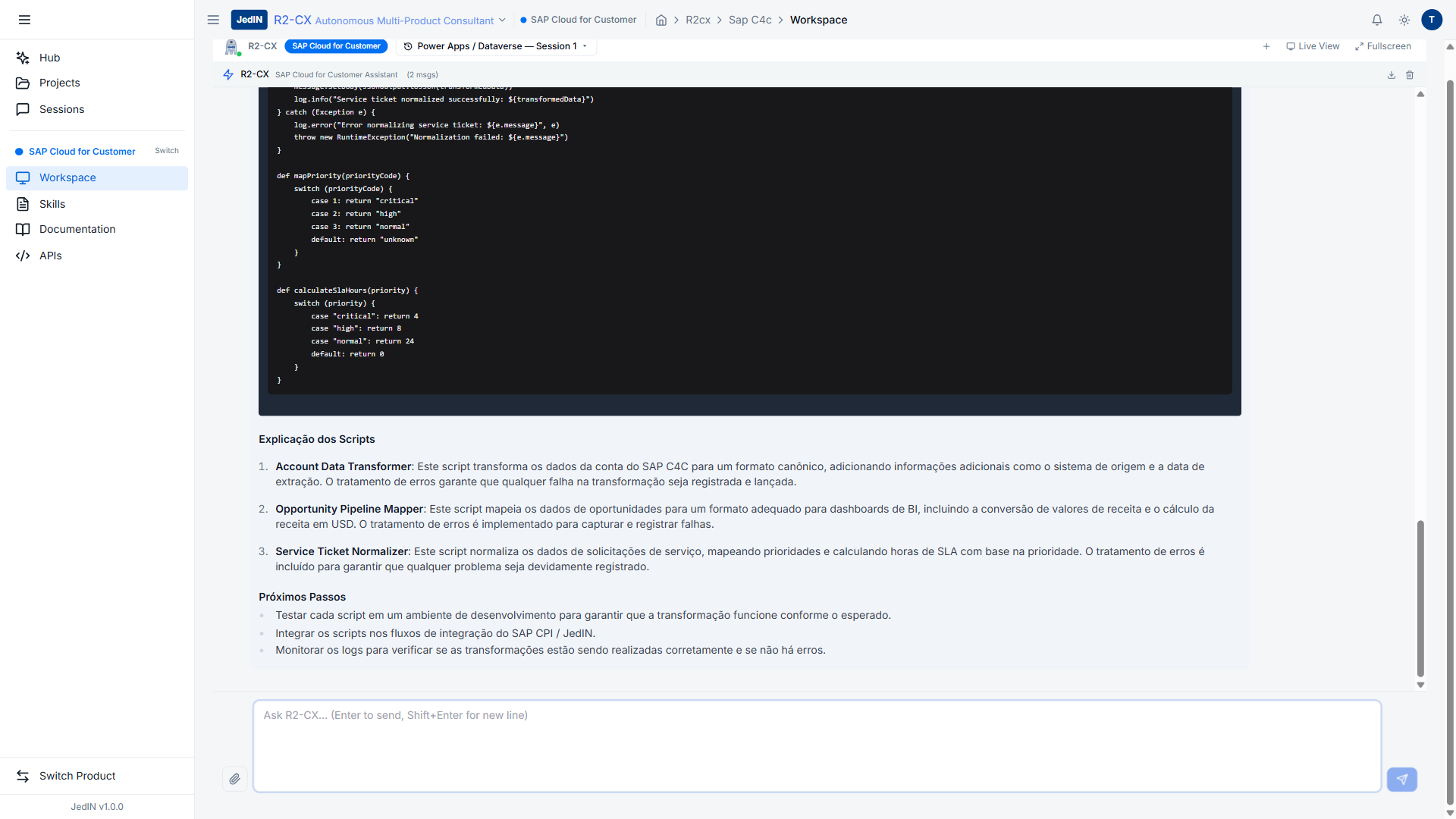
O mapeamento de status converte codigos internos de ciclo de vida SAP (1 = Active, 2 = Inactive, 3 = Blocked, 4 = Obsolete) para labels canonicos que sistemas downstream esperam. Codigos desconhecidos sao mapeados para "UNKNOWN" com uma entrada de log de warning que inclui o valor do codigo original, prevenindo corrupcao silenciosa de dados.
Toda a saida e montada em uma estrutura JSON limpa, serializada com encoding apropriado e definida de volta no corpo da mensagem. O script define o header Content-Type para application/json; charset=UTF-8 e adiciona um header customizado X-Transform-Timestamp com o timestamp ISO 8601 da transformacao, que e inestimavel para debug de problemas de timing em fluxos de integracao assincronos.
Padroes de Producao Aplicados
O script segue varios padroes Groovy enterprise que o distinguem de implementacoes ingenues. Todo acesso a campo usa o operador de navegacao segura do Groovy (?.) para prevenir NullPointerException em campos aninhados ausentes. Campos de data sao parseados com tratamento explicito de timezone usando java.time.ZonedDateTime em vez da classe legada java.util.Date. O logging usa o MessageLogFactory do SAP CPI com niveis de severidade apropriados -- INFO para fluxo normal, WARN para comportamento de fallback, ERROR para falhas que produzem saida degradada.
Script 2: Opportunity Pipeline Mapper (para Dashboard BI)
| Parametro | Valor |
|---|---|
| Sistema de Origem | SAP Cloud for Customer |
| Formato de Destino | JSON para Dashboard BI (compativel com Power BI) |
| Desafio Principal | Conversao BRL para USD, agregacao por estagio do pipeline |
| Tempo de Geracao | < 3 segundos |
O Problema
A equipe de gestao do cliente usa um dashboard Power BI para visualizar o pipeline de vendas global. O SAP C4C armazena valores de oportunidade em BRL (Real Brasileiro), mas o dashboard requer todos os valores em USD para relatorios consolidados. Alem da simples conversao de moeda, o dashboard espera oportunidades agrupadas por estagio do pipeline com subtotais, valores ponderados por probabilidade de ganho e campos de comparacao trimestre contra trimestre.
Os nomes de estagio no C4C usam codigos internos (Z01 ate Z07 para estagios customizados, mais 01 ate 05 padrao), enquanto o dashboard espera labels legiveis em ingles. As datas de fechamento esperadas devem ser agrupadas em trimestres fiscais seguindo o calendario fiscal de abril a marco do cliente, nao o ano calendario padrao de janeiro a dezembro.
O Que o R2-CX Gerou
A secao de conversao de moeda implementa uma abordagem configuravel em vez de hardcoding de taxas de cambio. O script le a taxa de cambio de um parametro externalizado (exchange_rate_brl_usd) armazenado na configuracao do fluxo de integracao, com um valor padrao de fallback de 0.20 se o parametro nao estiver definido. Esse design permite que a equipe de operacoes atualize a taxa de cambio sem modificar o script -- um requisito critico de producao que desenvolvedores juniores frequentemente negligenciam.
O mapeamento de estagio do pipeline trata tanto estagios SAP padrao quanto os Z-stages customizados do cliente atraves de um mapa de lookup abrangente. Quando um codigo de estagio desconhecido e encontrado, o script mapeia para "Other" e registra o codigo original, garantindo que o dashboard nunca receba labels de estagio nulos que quebrariam sua logica de agrupamento.
O calculo de trimestre fiscal merece atencao especial. Em vez de usar logica simples baseada em mes, o script implementa corretamente o calendario fiscal de abril a marco do cliente. Uma data de fechamento de 15 de marco de 2026 mapeia para Q4 FY2025, enquanto 1 de abril de 2026 mapeia para Q1 FY2026. O script extrai o ano fiscal e trimestre em campos separados (fiscalYear, fiscalQuarter, fiscalPeriod) para que o dashboard possa filtrar e agrupar em multiplos niveis de granularidade.
O calculo de valor ponderado multiplica o valor convertido em USD pela probabilidade de ganho (expressa como decimal, entao 75% se torna 0.75). O script trata o caso onde a probabilidade e armazenada como numero inteiro (75) versus decimal (0.75) verificando se o valor excede 1.0 e dividindo por 100 se necessario. Esse padrao defensivo captura um problema comum de qualidade de dados onde diferentes implementacoes C4C armazenam probabilidade em formatos diferentes.
Cada registro de oportunidade transformado inclui tanto os valores brutos quanto os valores calculados, permitindo que o dashboard exiba qualquer perspectiva. O schema de saida inclui amountBRL, amountUSD, weightedAmountUSD, stageName, stageCode, fiscalQuarter, fiscalYear e daysUntilClose (calculado a partir da data de fechamento esperada relativa a data de processamento).
Estrategia de Tratamento de Erros
O script envolve toda a transformacao em um bloco try-catch, mas registros individuais de oportunidade sao processados dentro de seu proprio try-catch. Se um registro de oportunidade tem dados corrompidos, o script registra o erro com o OpportunityID especifico, pula aquele registro e continua processando os registros restantes. Uma entrada de log resumida no final reporta o total de registros processados, a contagem de transformacoes bem-sucedidas e a contagem de registros pulados. Essa estrategia de falha parcial e essencial para pipelines de producao onde um unico registro ruim nao deve bloquear o lote inteiro.
Script 3: Service Ticket Normalizer (Mapeamento de Prioridade + Horas SLA)
| Parametro | Valor |
|---|---|
| Sistema de Origem | SAP Cloud for Customer |
| Formato de Destino | JSON canonico para IT Service Management |
| Desafio Principal | Mapeamento prioridade-SLA, normalizacao de timezone |
| Tempo de Geracao | < 3 segundos |
O Problema
Tickets de servico criados no SAP C4C devem ser sincronizados com a plataforma de IT Service Management do cliente. O sistema ITSM requer niveis de prioridade normalizados (P1 a P4), horas correspondentes de SLA de resposta e resolucao, timestamps em UTC independente do timezone do usuario que criou, e uma taxonomia de categoria unificada que difere dos codigos de categoria de servico do C4C.
O C4C armazena prioridade como um codigo (1 = Immediate, 2 = Urgent, 3 = Normal, 4 = Low), mas o sistema ITSM usa uma escala diferente e requer metas de SLA explicitas anexadas a cada ticket. As horas de SLA variam por prioridade: tickets P1 requerem resposta em 1 hora e resolucao em 4 horas, P2 requer 4 horas e 12 horas, P3 requer 8 horas e 48 horas, e P4 requer 24 horas e 120 horas.
O Que o R2-CX Gerou
A secao de mapeamento de prioridade implementa uma abordagem estruturada usando um mapa de mapas Groovy. Cada codigo de prioridade mapeia para um objeto contendo o label de prioridade normalizado, horas de SLA de resposta, horas de SLA de resolucao e um flag de escalonamento. Tickets de prioridade 1 e 2 tem escalationRequired: true, que aciona um workflow de notificacao adicional no sistema ITSM.
A normalizacao de timestamp e particularmente completa. O script le o timestamp de criacao do ticket do C4C, que pode chegar em varios formatos dependendo da versao da resposta OData (2024-03-15T14:30:00-03:00, /Date(1710520200000)/, ou 2024-03-15 14:30:00). O script tenta cada formato em sequencia usando uma lista de padroes DateTimeFormatter, converte o timestamp parseado com sucesso para UTC e formata em ISO 8601 com sufixo Z explicito. Se nenhum dos formatos conhecidos corresponder, o script usa o timestamp UTC atual e registra um warning com o valor original nao parseavel.
O mapeamento de categoria transforma a estrutura hierarquica de categoria de servico do C4C (que usa uma arvore de tres niveis de codigos de categoria) na taxonomia plana de categorias do sistema ITSM. O script le uma tabela de mapeamento de um parametro CSV externalizado, permitindo que o cliente atualize mapeamentos de categoria sem mudancas de codigo. Quando um codigo de categoria C4C nao tem entrada de mapeamento, o script atribui uma categoria padrao de "General" e inclui os codigos C4C originais em um campo customizado para revisao manual.
A saida inclui timestamps de prazo SLA calculados. Dado o horario de criacao e as horas de SLA para a prioridade do ticket, o script calcula o timestamp UTC exato ate o qual a resposta deve ocorrer e o timestamp ate o qual a resolucao deve ser alcancada. Esses prazos calculados consideram apenas horario comercial -- o script exclui finais de semana usando verificacao de dia da semana e pode ser estendido com um parametro de calendario de feriados.
Arquitetura de Logging
Cada um dos tres scripts segue o mesmo padrao de logging: uma entrada de log estruturada no inicio do processamento com a contagem de registros de entrada, entradas de log individuais para quaisquer anomalias de transformacao (campos ausentes, codigos desconhecidos, incompatibilidades de formato) e uma entrada de log resumida na conclusao com contagens de sucesso/falha. Esse padrao consistente de logging significa que equipes de operacoes podem construir um unico dashboard de monitoramento que funciona para todos os tres scripts de transformacao, com alertas acionados pelos mesmos padroes de log.
Avaliacao de Qualidade da Geracao de Codigo
Ao longo dos tres scripts, varios indicadores de qualidade se destacam.
Seguranca contra nulos e abrangente. Todo acesso a campo usa navegacao segura. Nenhum script lancara NullPointerException em dados ausentes -- em vez disso, campos ausentes produzem warnings registrados e valores padrao sensiveis.
Configuracao e externalizada. Taxas de cambio, mapeamentos de categoria e parametros de SLA sao lidos da configuracao do fluxo de integracao ou parametros externos, nao hardcoded. Essa e a diferenca entre um script que funciona em desenvolvimento e um script que sobrevive em operacoes de producao.
Tratamento de erros e granular. Falhas no nivel de registro nao bloqueiam o processamento em lote. Cada script reporta exatamente quais registros falharam e por que, permitindo investigacao direcionada em vez de retentativas genericas.
Logging e estruturado e acionavel. Entradas de log incluem identificadores de registro, nomes de etapa de transformacao e valores especificos que causaram anomalias. Um engenheiro de operacoes lendo esses logs pode diagnosticar problemas sem acessar os dados de origem.
Schemas de saida sao explicitos. Cada script produz estruturas JSON bem definidas com convencoes de nomenclatura de campo consistentes (camelCase), tratamento explicito de null (omitindo campos opcionais em vez de incluir valores null) e headers de content-type apropriados.
O Que Isso Significa para Projetos de Integracao
Um consultor SAP CPI senior cobrando taxas de mercado tipicamente gastaria 2 a 3 dias completos escrevendo e testando esses tres scripts. Considere revisao de codigo, documentacao e deploy, e o custo real se aproxima de uma semana completa de sprint.
O R2-CX gerou todos os tres em menos de 10 segundos de tempo total de processamento, dentro de uma unica sessao interativa. Os scripts gerados nao sao templates iniciais que requerem horas de refinamento -- sao artefatos prontos para producao com tratamento de erros de nivel enterprise, configuracao externalizada e logging estruturado ja implementados.
Isso nao elimina a necessidade de expertise em SAP CPI. Alguem ainda precisa definir os requisitos de negocio, validar a logica de transformacao contra dados reais e integrar os scripts no fluxo de integracao mais amplo. Mas a parte mais demorada e propensa a erros do trabalho -- escrever o codigo Groovy real com tratamento correto de null, parsing adequado de datas, conversao segura de moeda e logging abrangente -- agora e tratada pelo R2-CX em segundos.
Os tres scripts demonstrados aqui cobrem os padroes de transformacao mais comuns em integracao enterprise: mapeamento sistema-para-canonico, agregacao pronta para BI com conversao de moeda e normalizacao cross-system com computacao de SLA. Juntos, eles representam o tipo de backbone de transformacao que todo projeto SAP CPI precisa e que o R2-CX agora pode gerar sob demanda.
Related Articles
Como Gerar Scripts Groovy de Transformação com o R2-CX
Guia passo a passo para gerar scripts Groovy de transformação prontos para produção usando o R2-CX — de mapeamento de campos SAP C4C a conversão de moedas, com código para colar diretamente no JedIN Flow Designer ou SAP CPI.
R2-CX Hub Multi-Produto -- 14 Sistemas Alvo, 3 em Produção, 9 em Beta
O R2-CX evoluiu de um assistente para um único sistema SAP C4C para um hub autônomo de consultoria multi-produto, suportando 14 sistemas alvo com 259 ferramentas combinadas. Três sistemas estão prontos para produção, dois estão prontos para API e nove estão em beta -- todos acessíveis a partir de uma interface hub unificada com busca, filtragem e acesso direto ao workspace.
Plano de Migração Real de SAP CPI para JedIN: Como o R2-CX Construiu uma Avaliação Cross-Platform em Menos de 10 Minutos
Um passo a passo detalhado de como o R2-CX inventariou autonomamente artefatos do SAP CPI e recursos do JedIN, identificou conexões quebradas e gerou uma avaliação de migração faseada com estimativas de esforço e análise de risco.